Week 9 practical
Audio recording, more randomisation stuff, custom preload lists, conditional timelines, reading trial lists from CSV
The plan for week 9 practical
This week we are going to look at code for a confederate priming experiment based on the experiment described in Loy & Smith (2021) (and in fact using our stimuli). We are also going to add a few more bits and pieces involving randomisation (random participant IDs, random wait durations to simulate a human partner), we’ll build a custom preload list to make sure our button images are preloaded before the experiment starts (using an alternative technique to the one used in the answer to one of the harder questions from last week), we’ll show you how to include a conditional timeline (trials that only run if the participant gave a certain response on a previous trial), and finally I’ll show how to load a trial list from a CSV file (handy if you want to use a pre-built trial list).
Acknowledgments
For this demo experiment we are using audio stims recorded by my RA Rachel Kindellan, who was the confederate in Loy & Smith (2021). The images are the ones we used in the experiments described in the paper.
A confederate priming experiment
First: you build (some of) it!
As with last week, we’d like to give you an opportunity to try to build (parts of) this experiment yourself, and we’ll provide you with a template that we pre-built for you so you can focus on the more interesting parts of the experiment.
You need a bunch of files for this experiment - html and js files for several versions of the experiment, two php files (for saving CSV and audio data), plus various folders containing images, sounds, trial lists etc. Again, rather than downloading them individually, download the following zip file:
As usual, extract this and copy the folder into your practicals folder on the jspsychlearning server - since data (including audio) won’t save if you run it locally, by this point you really want to be at least testing everything on the jspsychlearning server. Furthermore, there are a couple of things to note before you can run our implementation of the code:
- Our code will save audio files to a subfolder of
server_datacalledaudio- so you need to create that subfolder. You can create new folders in cyberduck quite easily, but you have to create this new folder in exactly the right way to make sure the folder permissions (rules about who can write to the folder) are set correctly, otherwise your audio may not save. Go to yourserver_datafolder in cyberduck and go into the folder (i.e. double-click it) so your cyberduck window looks like this - note that my navigation bar shows me I am in/home/ksmith7/server_data, yours will show you as in/home/UUN/server_datadepending on what your UUN is.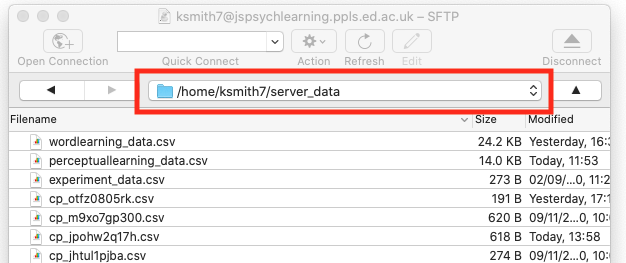 Then click the “action” button (with the cog), select the “New folder…” option and call the new folder
Then click the “action” button (with the cog), select the “New folder…” option and call the new folder audio(with that exact name, i.e. lower-case first letter). That should create a folder in the correct place with the correct permissions! - You may need to use Chrome for the audio recording to work reliably - feel free to try out other browsers, but if the audio recording doesn’t work, try it in Chrome first before seeking our help!
If your directory structure is as I have been using so far, where all the exercises are in a folder called online_experiments_practicals, then the url for your implementation will be https://jspsychlearning.ppls.ed.ac.uk/~UUN/online_experiments_practicals/confederate_priming/my_confederate_priming.html and the URL for the final implementation will be https://jspsychlearning.ppls.ed.ac.uk/~UUN/online_experiments_practicals/confederate_priming/confederate_priming.html
If you run through our implementation of the experiment you’ll see that the experiment consists of two trial types, which alternate:
- Picture selection trials, where participants hear audio from their partner (in fact, pre-recorded audio from our confederate) and select the matching picture from an array of 2 pictures.
- Picture description trials, where participants see two pictures side by side and produce a description for one of them (the target) for their partner, clicking a mic icon to start and stop recording.
We are interested in whether, on critical trials featuring an opportunity to produce an unnecessary colour word, the descriptions produced by the confederate (which consistently overspecify or avoid overspecifying) influences the descriptions the participant produces.
Implementing something like this in full involves some technical steps you haven’t seen yet, in particular recording audio and displaying stimuli which consist of pairs of images. The current version of jsPsych provides one plugin for audio responses, html-audio-response` - this is currently in development, so it doesn’t work perfectly (see our comments below), but you can use it to have a go at implementing this experiment in full, recording audio and all. Or you can just try to get something that looks along the right lines (hearing the confederate speak and selecting from two pictures; seeing a picture and clicking a mic button) without worrying about the audio recording at this point. And if you’d rather just jump to our implementation to see how we do it, that’s fine.
The sound files and images you will want to play around with are in the sounds and images folders that you get in the zip file. Note that the audio and image files have quite abstract names - this was something that Jia came up with that made it easy for her to manage a large list of paired image and audio files. You can look in the images and sounds folders to work this out, but to help you:
For images:
Faces: “f_fr1” is female face, frightened emotion, face number 1 (we have several faces for each emotion); “f_ha2” is happy female face number 2. Male faces start with “m_” rather than “f_” - e.g. “m_fr3” would be frightened male face number 3.
Fruit and veg: these are named “frv1” (apple) through to “frv16” (watermelon).
Animals: these are named “ani1” (camel) through to “ani16” (zebra).
Garments: These are one of our two sets of critical items which differ in colour. “g4_c1” is garment 4 (a sock) in colour 1 (red); “g2_c3” is garment 2 (a glove) in colour 3 (green).
Kitchen items: This is our other set of critical items. “k1_c1” is kitchen item 1 (a bowl) in colour 1 (red); “g2_c2” is kitchen item 2 (a fork) in colour 2 (blue).
For sounds:
The sound files are all matched to the image files of the same name - e.g. the image file “g4_c1” has some corresponding sound files whose name starts with “g4_c1” where Rachel (our confederate) says “the red sock”. But to inject a bit of variation and make it less obvious these are pre-recorded, we have several versions of some sound files - e.g. there are two recordings of Rachel saying “the red sock”, which are named “g4_c1_1” and “g4_c1_2”. We also have sound files with just the bare noun (e.g. “the sock” rather than “the red sock”), e.g. “g4_1” and “g4_2” are Rachel saying “the sock” a couple of different ways.
Our implementation
There are actually two implementations of the experiment included in the zip file for you:
- A short version with a small number of trials. The code for this is in
confederate_priming.htmlandconfederate_priming.js, and the URL will be https://jspsychlearning.ppls.ed.ac.uk/~UUN/online_experiments_practicals/confederate_priming/confederate_priming.html if your directory structure is as suggested in previous weeks. This is the code I will start with in the explanation below. - A full-length version with a large number of trials (100+). The code for this is in
confederate_priming_readfromcsv.htmlandconfederate_priming_readfromcsv.js, and the URL should be https://jspsychlearning.ppls.ed.ac.uk/~UUN/online_experiments_practicals/confederate_priming/confederate_priming_readfromcsv.html. If you want a longer demo you can run this, but the main purpose of including the second version is to show you how a long trial list can be read in from a CSV file.
Picture selection trials in our implementation work in essentially the same way as picture selection trials in the perceptual learning experiment, using the audio-button-response plugin, so not much new stuff there.
The main part of the picture description trial is an html-audio-response trial (with an html-button-response trial beforehand, so the participant clicks on a mic button to enter the audio response trial and start recording). One reason we are using html-audio-response (i.e. an html stimulus, even though our stimulus involves images) is that that’s the only audio response plugin currently available in jsPsych! There is no image-audio-response plugin yet, although I imagine that will be added soon. But in fact it works out quite nicely, because our picture description trials involve presenting two side-by-side images, one highlighted with a green box, and it turns out it is easier to do this using an html stimulus rather than an image stimulus - this is explained below! Since the html-audio-response is new it’s not quite as slick as the more established plugins though, which means things look a little scrappy and, at the time of writing, there is a small bug in the plugin. It’s not disastrous, but if you wanted a different way to record audio you could consult the equivalent practical from last year, which doesn’t use the audio response plugin.
We also simulate the confederate preparing to speak and making a selection based on the participant’s productions by inserting variable-duration delays at appropriate points. The full experiment also included disfluencies etc (you can see some of the sound files for those if you go digging in the sounds folder) but we’ll keep it simple here.
Random participant IDs and random delays
The first part of confederate_priming.js is some notes and then some code for saving our data trial by trial - the function save_confederate_priming_data saves trial data in the same way as the save_perceptual_learning_data function from last week, and you’ll see it used in the functions below. Since you have seen similar functions before, I’ll skip these - there is a little bit of added complexity in there in that we want to record slightly different data for our two trial types, but you can look at the code and comments if you are interested.
The next thing in the code is a couple of functions for handling random elements of the experiment.
First, we are going to assign each participant a random participant ID - this means we can save one CSV file and one set of audio recordings per participant, rather than cramming everything into a single file as we have been doing so far. We create these random IDs using a jsPsych built-in function:
var participant_id = jsPsych.randomization.randomID(10);
This creates a variable, participant_id, which we can use later. The participant IDs are a string of randomly-generated letters and numbers, in this case set to length 10 (e.g. “asqids6sn1”) - since there are many many possible combinations of length 10 (36 to the power 10, which is more than 3,600,000,000,000,000) in practice this should mean that no two participants are assigned the same ID, and therefore each participant has a unique ID. Depending on how you set up your experiment, on some crowdsourcing platforms you might want to access the participant’s platform-specific ID rather than generating a random one (e.g. every participant on Prolific has a unique ID), we’ll show you how to do that in the final week of the course, it’s easy. But for now we’ll just generate a random ID per participant.
At various points in the experiment we also want to create a random-length delay, to simulate another participant composing their description or selecting an image based on the genuine participant’s description. In the Loy & Smith (2021) paper we had a fairly intricate system for generating these random delays, making them quite long initially (to simulate a partner who was not yet used to the task) and then reducing over time (to simulate increasing familiarity, but also not to needlessly waste our real participants’ time); we also inserted various kinds of disfluencies, particularly early on. My impression is that this was reasonably successful - we have run a number of experiments with this set-up and not too many participants guessed they were interacting with a simulated partner - and also worth the effort, in that most of the people who did guess that they were not interacting with a real person were cued by their partner’s response delays, in particular, noting that they were quite short and quite consistent.
In the demo experiment, for simplicity’s sake we just create a function which returns a random delay between 1800ms and 3000ms, using some built-in javascript code for random number generation:
function random_wait() {
return 1800+(Math.floor(Math.random() * 1200))
}
Math.random() generates a random number between 0 and 1 (e.g 0.127521, 0.965341). We then multiply that by 1200 and use Math.floor to round down to a whole number (e.g. our random numbers will become 255, 1130 respectively), then add 1800ms to produce random waits in our desired range (e.g. 2055ms, 2930ms).
Picture selection trials
Now we are in a position to start coding up our main trial types. We’ll start with picture selection trials, which work in a very similar way to picture selection trials in the perceptual learning experiment - participants hear some audio and then click on an image button, which is pretty straightforward using the audio-button-response plugin. The only added complication here is that we want to simulate another person thinking for a moment before starting their description. Unfortunately there’s no built-in way to do this within the audio-button-response plugin - I was hoping for a delay_before_playing_audio parameter or something, but there’s no such thing. The solution is to have a sequence of two trials that looks like a single trial - one trial where nothing happens (to simulate the wait for the confederate to speak), then the actual audio-button-response trial where we get the audio from the confederate. I built these both using the audio-button-response trial - on the waiting trial we just play a tiny bit of silence as the stimulus (the plugin won’t allow us to have no sound, so this was the closest I could get) and wait for a random duration, ignoring any clicks the participant makes, then we move on and play the confederate audio.
As usual, we’ll write a function where we specify the main parts of the trial (the audio file the participant will hear, which I am calling sound; the target image, the foil or distractor image) and then the function returns a complex trial object for us. Here’s the full chunk of code, I’ll walk you through it piece by piece below:
function make_picture_selection_trial(sound, target_image, foil_image) {
//add target_image and foil_image to our preload list
images_to_preload.push(target_image);
images_to_preload.push(foil_image);
//create sound file name
var sound_file = "sounds/" + sound + ".wav";
//generate random wait and random order of images
var wait_duration = random_wait();
var shuffled_image_choices = jsPsych.randomization.shuffle([
target_image,
foil_image,
]);
//trial for the delay before the partner starts speaking
var waiting_for_partner = {
type: jsPsychAudioButtonResponse,
stimulus: "sounds/silence.wav",
prompt: "<p><em>Click on the picture your partner described</em></p>",
choices: shuffled_image_choices,
trial_duration: wait_duration,
response_ends_trial: false, //just ignore any clicks the participant makes here!
button_html:
'<button class="jspsych-btn"> <img src="images/%choice%.png" style="width:250px"></button>',
};
//audio trial
var selection_trial = {
type: jsPsychAudioButtonResponse,
stimulus: sound_file,
prompt: "<p><em>Click on the picture your partner described</em></p>",
choices: shuffled_image_choices,
button_html:
'<button class="jspsych-btn"> <img src="images/%choice%.png" style="width:250px"></button>',
post_trial_gap: 500, //a little pause after the participant makes their choice
on_start: function (trial) {
trial.data = {
participant_task: "picture_selection",
button_choices: shuffled_image_choices,
};
},
on_finish: function (data) {
var button_number = data.response;
data.button_selected = data.button_choices[button_number];
save_confederate_priming_data(data); //save the trial data
},
};
var full_trial = { timeline: [waiting_for_partner, selection_trial] };
return full_trial;
}
First, we need to do some book-keeping.
We add the images we are going to show to a list we are building up, called images_to_preload - I will say what this is for when I talk about preloading later!
//add target_image and foil_image to our preload list
images_to_preload.push(target_image);
images_to_preload.push(foil_image);
We add the path for the sound file (all our sound files are in the sounds directory and have .wav on the end)
//create sound file name
var sound_file = "sounds/" + sound + ".wav";
We then do some randomisation stuff: we generate a random wait using our random_wait function (for the period of silence before the confederate starts speaking), and we shuffle the order in which the two images will be displayed on-screen. Note that we are doing this here, when we create the trial, rather than in the on_start, because our picture selection trial is actually going to have a sequence of two trials in it, and we want them to have the pictures in the same order (it would be super weird if the order of the images flipped part-way through the trial!). There are several ways this could be achieved, I thought this was the simplest.
//generate random wait and random order of images
var wait_duration = random_wait();
var shuffled_image_choices = jsPsych.randomization.shuffle([
target_image,
foil_image,
]);
Our random wait is then an audio-button-response trial, where the participant sees the two image buttons on screen, but we ignore anything they click on (response_ends_trial is set to false), and we set trial_duration to the random wait we generated earlier. As in the perceptual learning experiment, we are using the button_html parameter to make our buttons appear as images rather than text.
//trial for the delay before the partner starts speaking
var waiting_for_partner = {
type: jsPsychAudioButtonResponse,
stimulus: "sounds/silence.wav",
prompt: "<p><em>Click on the picture your partner described</em></p>",
choices: shuffled_image_choices,
trial_duration: wait_duration,
response_ends_trial: false, //just ignore any clicks the participant makes here!
button_html:
'<button class="jspsych-btn"> <img src="images/%choice%.png" style="width:250px"></button>',
};
Our actual selection trial requires quite a large block of code to generate it (see the big chunk of code above, where we create selection_trial), but this is all stuff you have seen before - an audio-button-response trial, where we add some stuff to the trial data on_start, and then work out which button the participant actually clicked on_finish, saving the trial data to the server using the save_confederate_priming_data function.
Finally, we stick our waiting trial and our picture selection trial together as a single trial consisting of just a timeline and returning that two-part trial.
var full_trial = {timeline:[waiting_for_partner,selection_trial]};
return full_trial
Later on we will use this make_picture_selection_trial function to create picture selection trials to stick in the experiment timeline.
Picture description trials
These involve the participant recording an audio description of a target image. Before we can do any audio recording we have to get the participant to grant us mic access, have them select which mic they use, and also set up a function for saving audio data. This is all in the code in the section “Infrastructure for recording audio”, you can look there for the easy bits, I’ll talk you through the save_audio function below.
Once the audio stuff is set up we create our picture description trials - remember, for these the participant sees two images side by side, with the target highlighted by a green box, clicks a button to start recording a description, clicks again to stop recording, and then “waits for their partner to make a picture selection” based on their description (in reality, the participant just gets a waiting message and waits for a random time). This can be achieved with a 3-part timeline: the initial part of the trial where the participant sees the pair of images and clicks a button to start recording, then the second part where they speak and then click again to stop recording, then the random wait.
That sounds reasonably straightforward, but we have a slight issue in that we want to show two images side by side. There are a couple of ways around this. We could write our own plugin that shows two images (but messing with plugins can be a little intimidating); we could make a whole bunch of image files that contain two images side by side (but given the number of images we have that will be a huge number of composite images!); or we can use another more flexible plugin with an html stimulus - that is my preferred option, which is convenient since the only audio response plugin currently implemented is html-audio-response!
The stimulus for html-audio-response is an html string (obviously), and since html can include images that means I can create an html stimulus that contains two images side by side. For example, if I want to show two images (imagine they are called image1.png and image2.png) side by side in html then this will work:
var composite_image ="<img src=image1.png> <img src=image2.png>";
That’s a valid piece of html that uses image tags to include two images in a single piece of html, and it will work fine as the stimulus for an html-audio-response trial. If we want to make the images the same size and add a green box around one of them (to identify it as the target) then we need slightly more complex html, but the same idea:
var composite_image ="<img src=image1.png style='border:5px solid green; width:250px'> <img src=image2.png style='width:250px'>";
The extra stuff sets the image width (you have seen something similar before) and the border (it took me a while and quite a lot of googling and trial-and-error to figure that out).
So that’s how we get two images into an html stimulus. Our picture description trial therefore consists of two trials: an html-button-response trial and then an html-audio-response trial, both with the same stimulus, the composite side-by-side images. The first trial allows the participant to click to begin recording, then it moves to the html-audio-response trial which starts recording immediately. The reason I have the first trial in there is that I don’t like the idea of recording without the participant doing something to start the recording, and I think the click-to-start, click-to-end set-up is reasonably intuitive. It actually looks a little bit jumpy on-screen - as mentioned above, the html-audio-response plugin is new and it’s not formatted exactly the same as the html-button-response plugin (everything is slightly higher up the screen), so you can see the join between the two trials. Also, they haven’t implemented the prompt for the html-audio-response plugin yet, so to get something prompt-like on screen in the same place on both trials I have to add that to the stimulus too. But these little glitches won’t make a huge difference to your experiment, and will no doubt be ironed out.
Again, we write a function which builds this complex trial for us - we pass in the target image to be described plus the foil image, it returns the complex trial for us. The full code is here, I’ll walk you through it below:
function make_picture_description_trial(target_image, foil_image) {
//add target_image and foil_image to our preload list
images_to_preload.push(target_image);
images_to_preload.push(foil_image);
//generate random wait and random order of images
var wait_duration = random_wait();
//need to highlight the target with a green border
var target_image_as_html =
"<img src=images/" +
target_image +
".png style='border:5px solid green; width:250px'>";
var foil_image_as_html =
"<img src=images/" + foil_image + ".png style='width:250px'>";
//shuffle and paste together into a composite bit of html
var shuffled_images = jsPsych.randomization.shuffle([
target_image_as_html,
foil_image_as_html,
]);
var composite_image = shuffled_images[0] + shuffled_images[1];
var composite_image_with_prompt =
composite_image + "<p><em>Describe the picture in the green box</em></p>";
//html button response
var picture_plus_white_mic = {
type: jsPsychHtmlButtonResponse,
stimulus: composite_image_with_prompt,
choices: [
'<img src="images/mic.png" style="background-color:white; width:75px">'
],
};
var record_audio = {
type: jsPsychHtmlAudioResponse,
stimulus: composite_image_with_prompt,
recording_duration: 10000,
done_button_label:
'<img src="images/mic.png" style="background-color:Darkorange; width:75px">',
on_finish: function (data) {
data.participant_task = "picture_description";
data.target = target_image;
data.foil = foil_image;
save_audio(data);
save_confederate_priming_data(data);
},
};
var waiting_for_partner = {
type: jsPsychHtmlButtonResponse,
stimulus: "Waiting for partner to select",
choices: [],
trial_duration: wait_duration,
post_trial_gap: 500, //short pause after the confederate makes their selection
};
var full_trial = {
timeline: [picture_plus_white_mic, record_audio, waiting_for_partner],
};
return full_trial;
}
Let’s step through that chunk by chunk. First we do some book-keeping - as with the picture selection trials, we keep track of image names for later preloading…
//add target_image and foil_image to our preload list
images_to_preload.push(target_image);
images_to_preload.push(foil_image);
…and we generate a random wait (for the screen at the end).
//generate random wait
var wait_duration = random_wait();
Next we are going to do some html formatting of our target and foil image, as described above - we’ll put them in image tags, and put the green border around the target.
//need to highlight the target with a green border
var target_image_as_html =
"<img src=images/" +
target_image +
".png style='border:5px solid green; width:250px'>";
var foil_image_as_html =
"<img src=images/" + foil_image + ".png style='width:250px'>";
Now we have our target and foil images with the necessary formatting, we can shuffle the order and paste them together:
//shuffle and paste together into a composite bit of html
var shuffled_images = jsPsych.randomization.shuffle([
target_image_as_html,
foil_image_as_html,
]);
var composite_image = shuffled_images[0] + shuffled_images[1];
shuffled_images[0] takes whatever is the first thing in shuffled_images, so this will end up with either of the target or foil image (appropriately formatted) appearing on the left.
As mentioned above, we want something like a prompt, telling the participant what to do, but the html-audio-response plugin doesn’t have a prompt, so we have to achieve the same sort of effect by adding the prompt to our composite html stimulus:
var composite_image_with_prompt =
composite_image + "<p><em>Describe the picture in the green box</em></p>";
Now we have the first sub-trial where the participant sees the composite image plus a “start recording” button and clicks to begin recording. This is just an html-button-response trial:
var picture_plus_white_mic = {
type: jsPsychHtmlButtonResponse,
stimulus: composite_image_with_prompt,
choices: [
'<img src="images/mic.png" style="background-color:white; width:75px">',
],
};
The participant’s choices on this trial is just the mic button - we use the mic image file, which is in the images folder, and do a little bit of formatting so the mic image appears with a white background (which we’ll change below to orange to indicate they are recording).
When the participant is ready they click the mic button, which progresses them to the next trial. This is where the action happens: it’s an audio response trial, so the audio is recorded for us, and we indicate they are recording by turning the mic button orange. When they click the mic button again the trial will end, stopping the recording, and we save the trial data and the audio recording. The code for all that looks like this:
var record_audio = {
type: jsPsychHtmlAudioResponse,
stimulus: composite_image_with_prompt,
recording_duration: 10000,
done_button_label:
'<img src="images/mic.png" style="background-color:Darkorange; width:75px">',
on_finish: function (data) {
data.participant_task = "picture_description";
data.target = target_image;
data.foil = foil_image;
save_audio(data);
save_confederate_priming_data(data);
},
};
A bunch of stuff is the same as in the picture_plus_white_mic trial - the composite stimulus, the mic button (although this is included in a slightly different place in the code, under done_button_label, and we change the background to orange) - so there is no big visual change for the participant (although as mentioned above, this plugin is not very polished yet so things do move a little bit). But we have also specify a recording_duration, 10000ms, which is the max duration of recording, so if the participant doesn’t stop the recording after 10 seconds it will stop recording. Audio recording can generate very large files that can crash the participant’s browser, so setting some limit is sensible. It should be possible to have an open-ended recording by setting recording_duration: null, but there’s a bug in the plugin at the moment that means this doesn’t work - again, new plugin, stuff needs ironed out, we have raised it as an issue!
Finally, when the participant is done talking they click the mic button again to stop recording - so in this trial’s on_finish parameter (which runs when they click the done button) we do some tidying up.
on_finish: function (data) {
data.participant_task = "picture_description";
data.target = target_image;
data.foil = foil_image;
save_audio(data);
save_confederate_priming_data(data);
},
We add some info to the trial’s data, including the fact that it’s a picture description task with a particular target and foil image. We also want to save the data from this trial, which we do using save_confederate_priming_data. And we also save the audio generated by this trial, using the save_audio function defined elsewhere in the code - see below.
Finally, we add the third sub-trial, a very simple waiting message using the random duration we generated earlier, and then build and return a trial with a nested timeline featuring our three trials (white mic, record audio, waiting message):
var waiting_for_partner = {
type: jsPsychHtmlButtonResponse,
stimulus: "Waiting for partner to select",
choices: [],
trial_duration: wait_duration,
post_trial_gap: 500, //short pause after the confederate makes their selection
};
var full_trial = {
timeline: [
picture_plus_white_mic,
record_audio,
waiting_for_partner,
],
};
return full_trial;
}
The only other thing we have to explain is the save_audio function. The code is below - this is very similar to our save_data function in that it basically hands off the job of saving the data to a PHP script. But we have to tell the PHP script what file name we want to save the audio under. Here we are using the format id_index.wav, where id is the random participant_id we generated and index is the trial_index. Every piece of trial data in jsPsych has an index (0 for the first trial in the experiment, e.g. the initial consent screen, 1 for the next trial, etc), and we write those trial indexes in our CSV file, so if we include the same index in the recording name we can work out which recording goes with which trial in our CSV. Here’s the full save_audio function. One additional note is that audio will be saved in server_data/audio/ by our save_audio.php script, so that’s where you’ll find it.
function save_audio(data) {
var audio_data = data.response;
var trial_index = data.trial_index;
var url = "save_audio.php";
var this_recording_filename = participant_id + "_" + trial_index + ".wav";
var data_to_send = {
filename: this_recording_filename,
data: audio_data,
};
fetch(url, {
method: "POST",
body: JSON.stringify(data_to_send),
headers: new Headers({
"Content-Type": "application/json",
}),
});
}
Building the interaction timeline
Now we can use these functions to build our timeline. We’ll start by building a set of interaction trials, which alternate picture selection and picture description trials, then add the usual instructions etc later. Here’s a set of 6 trials - the critical trials are 3 (the confederate describes a red sock using an overspecific description “the red sock”) and 6 (the participant describes a red bowl - will they say “the red bowl”, or just “the bowl”?).
var interaction_trials = [
//filler (confederate describes face)
make_picture_selection_trial("f_fr1", "f_fr1", "f_ha2"),
//filler (participant describes fruit/vegetable)
make_picture_description_trial("frv3", "frv12"),
//critical trial (confederate describes red sock using adjective)
make_picture_selection_trial("g4_c1_1", "g4_c1", "g2_c3"),
//filler (participant describes animal)
make_picture_description_trial("ani1", "ani15"),
//filler (confederate describes face)
make_picture_selection_trial("f_su3", "f_su4", "f_sa1"),
//critical trial (participant describes red bowl)
make_picture_description_trial("k1_c1", "k2_c2"),
];
We then combine interaction_trials with some other trials (information screens, trials to handle mic set-up etc) to produce the full experiment timeline.
A custom preload list
As I mentioned in last week’s practical, jsPsych’s preload plugin will pre-load images and audio for certain trial types, which makes the experiment run more smoothly and ensures that images you think participants are seeing have actually been loaded and are displaying. In particular, the image in image-button-response trials and the audio in audio-button-response trials are preloaded automatically if you include a preload plugin and set auto_preload: true. However, that won’t automatically preload images used as buttons in audio-button-response trials, which means our image buttons in picture selection trials will not be pre-loaded, and it doesn’t preload anything for html-button-response or html-audio-response trials, so our fancy composite images won’t be preloaded either. Fortunately the preload plugin allows you to specify an additional list of images to be preloaded, which we will use to preload these images.
While we could manually code up a preload list (boring) or just load all the images we might conceivably need (a bit naughty since we are probably wasting the participant’s bandwidth!), it’s possible to get the code to construct this custom preload list for us. You might have attempted this last week, where we played around with working through a trial list and identifying images to preload. This week we are actually taking a slightly different approach: every time we build a trial, we make a note of the images we will need to preload. So right near the top of the confederate_priming.js file you’ll find:
//initially our images_to_preload list contains only 1 image, the microphone!
var images_to_preload = ["mic"];
That creates a variable where we can store a list of the images we will need to pre-load - we always need the microphone image, so that is in there. Then, as you have already seen, every time we call our functions which create trials for us, we add some images to this list using push.
function make_picture_selection_trial(sound, target_image, foil_image) {
//add target_image and foil_image to our preload list
images_to_preload.push(target_image);
images_to_preload.push(foil_image);
...
function make_picture_description_trial(target_image, foil_image) {
//add target_image and foil_image to our preload list
images_to_preload.push(target_image);
images_to_preload.push(foil_image);
So by the time we have created all our trials, our images_to_preload variable will contain a list of image names for preloading, which we can use in the preload plugin. Or almost - we have to do a little extra work, to add the path and file type information to each image name, which we do with a for loop.
var images_to_preload_with_path = [];
for (image of images_to_preload) {
var full_image_name = "images/" + image + ".png";
images_to_preload_with_path.push(full_image_name);
}
/*
Now we can make our preload trial
*/
var preload = {
type: jsPsychPreload,
auto_preload: true,
images: images_to_preload_with_path,
};
A conditional timeline
If you have run through our implementation you will have noticed that we ask participants if they are native speakers of English, and if they answer “No” they are kicked out of the experiment (or rather, directed to an un-escapable holding screen). We didn’t actually do this in Loy & Smith (2021), but we wanted to show you that it was possible to do this kind of thing - if you do this for real, use it judiciously since participants may not like it, and make sure you provide more information for excluded participants on e.g. how they can get paid for any time they have spent on the experiment!
The way we achieve this is by a conditional timeline (see the jsPsych documentation). In a conditional timeline node you have a timeline which only runs if conditional_function evaluates to true - like this:
var conditional_node = {
timeline: [some_trials],
conditional_function: function () {
//return true if you want to do some_trials, false if you want to skip them
}
}
In our example, our conditional timeline consists of our single unescapable trial where we tell the participant they cannot proceed because we can only use native English speakers:
var nonnative_english_exclusion_screen = {
type: jsPsychHtmlButtonResponse,
stimulus:
"<p style='text-align:left'>Sorry, but we can only use native speakers of English in this experiment.</p>",
choices: [],
};
var native_english_check = {
timeline: [nonnative_english_exclusion_screen],
conditional_function: function () {
//return true and run the conditional timeline if they are a non-native speaker
}
}
How do we decide if they are a non-native speaker? We just ask them: before the native_english_check node we run a simple survey trial to pose the question:
var native_english_question = {
type: jsPsychSurveyMultiChoice,
questions: [
{
prompt: "Are you a native speaker of English?",
name: "NativeEnglish",
options: ["Yes", "No"],
required: true,
},
],
};
Then in our conditional_function in the conditional node we use the trick you have seen before for grabbing data from the previous trial to check if they said “No” (in which case we send them to the un-escapable screen), otherwise we skip that holding screen and therefore allow them to continue the experiment.
var native_english_check = {
timeline: [nonnative_english_exclusion_screen],
conditional_function: function () {
// get the data from the last trial
var data = jsPsych.data.get().last(1).values()[0];
//retrieve their answer to the question - this will be Yes or No
var answer = data.response.NativeEnglish;
if (answer == "No") {
//this means we *will* run the conditional timeline
return true;
} else {
//this means we will not
return false;
}
},
};
Here we are filtering people out based on their answer to a yes-no question, but you could do something similar based on their scores on a series of attention check trials or something. Just remember that you have to treat your participants fairly - if you eject people who have spent substantial time on your experiment and don’t give them an avenue to be reimbursed, they will rightly complain!
Advanced: reading the trial list from a CSV file
That’s probably enough for one week, so if you feel you have learned enough for today you can skim this section very fast and not worry about the details - we’ll actually cover something similar next week, so you’ll have two opportunities to see this technique. But if you can take a bit more, read on! You don’t have to master the details of this stuff, but getting the rough idea of how you read a trial list from a CSV might be useful.
The code above, which is in confederate_priming.html and confederate_priming.js, is perfectly adequate, and by adding more trials to interaction_trials you could fully replicate the Loy & Smith (2021) online experiments. However, the trial sequence in this experiment is pretty complex - as well as the correct sequence of primes, targets and fillers, we have to make sure we use all the objects and all the colours, get a mix of same-category and different-category prime-target fillers, and so on. For experiments with a complex trial sequence it’s often useful to build trial lists in advance (either manually, which would be hard and very boring, or using whatever programming language you are comfortable with), and then load those trial lists into the experiment.
If you look in the trial_lists folder you downloaded as part of the zip file for this week, you’ll see a couple of CSV files containing trial lists - one for an overspecific confederate, and one for a minimally specific confederate. You would want many such files for a real experiment, to avoid your participants all seeing the same trial sequence, but to keep it simple I’ll only show you two! Each line of those CSV files describes a trial: the participants role (in the column participantRole: director if they are producing the description, matcher if the confederate is speaking), the file name of the target and foil image (in the columns targetImage and distractorImage), and for trials where the confederate speaks the sound file to play (in soundFile) as well as some extra information telling us what trial type we are looking at (filler, prime or target) and the condition the file is for (overspecific or minimally specific).
We can read in these CSV files and use them to build a jsPsych trial list. That’s what confederate_priming_readfromcsv.html and confederate_priming_readfromcsv.js do. Most of the code is the same as the basic confederate_priming.js code, but at the end you’ll see some extra code for reading a CSV file into javascript and then converting it to a jsPsych trial list. The main function is read_trials_and_prepare_timeline - we specify the file name for a trial list and it reads it, creates a timeline and then runs it. Then we can start the experiment by running something like:
read_trials_and_prepare_timeline("overspecific_confederate.csv");
E.g. in this case, loading the overspecific confederate trial list. But how does this code work?
Reading a trial list from a CSV file in this way is slightly complicated, for two reasons. One reason is that we have to convert the text in the CSV file into something we can work with in javascript, which takes some time (the code contains two functions which do this, read_trial_list and build_timeline). But the other reason is that javascript behaves quite differently to other programming languages you may have used, in that it tries to run the code synchronously where it can - in other words, it doesn’t necessarily wait for one function to finish before it starts the next function running. This isn’t really noticeable unless you try running one function that is quite slow to execute and you need to use the output from that function as the input to another function, which is exactly what happens when we read a CSV file from the server and use it to build the trial list. You might think we could do something like:
var trial_list = read_trial_list(triallist_filename)
var interaction_trials = build_timeline(trial_list);
where read_trial_list gets the data from the CSV and then build_timeline turns it into a trial list that we can work with. However, this won’t work. Getting data from a CSV file on the server takes some time - only a fraction of a second, so it appears instantaneous to us, but for the computer this is very very slow. Rather than wait for read_trial_list to finish before it starts build_timeline, the browser will therefore press on and try to run build_timeline, but that will fail because the trial_list object which build_timeline needs as input doesn’t actually contain any data yet, because read_trial_list hasn’t finished!
How can we get around this problem? There are various solutions, but I think the simplest one is to use the async and await functions in newer versions of javascript. This allows us to declare some functions as async (i.e. asynchronous), and then use await to tell the browser to wait for a certain operation to complete before moving on. This means we can wait until the CSV file has been successfully read before we try to process the resulting data.
That’s how the read_trials_and_prepare_timeline function works - the full code is below, but this consists of the following steps:
- Read in the trial list from the CSV file using the
read_trial_listfunction - we willawaitthis result because we can’t proceed without it. To keep the code as simple as possible theread_trial_listfunction is defined in a separate javascript file,read_from_csv.js- if you look atconfederate_priming_readfromcsv.htmlyou’ll see we are loading this additional javascript file along with our plugins. You don’t have to look atread_from_csv.jsunless you want to - it’s fine if you treat the process of reading in the CSV file as a black box, and we’ll actually use a slightly different technique next week. - Use that trial list to build the interaction trials using the
build_timelinefunction, which basically reads the relevant columns from the CSV and uses themake_picture_selection_trialandmake_picture_description_trialfunctions we created earlier to make jsPsych trials. - Build our image preload list, which is just the same process as before but wrapped up in a function called
build_button_image_preloadso that it happens after we’ve made the trial list. - Stick that interaction timeline together with the instruction trials to produce our full timeline.
- And then run the full timeline.
In code, these steps look like this:
async function read_trials_and_prepare_timeline(triallist_filename) {
var trial_list = await read_trial_list(triallist_filename);
var interaction_trials = build_timeline(trial_list);
var preload_trial = build_button_image_preload();
var full_timeline = [].concat(
consent_screen,
audio_permission_instructions,
audio_permission_instructions2,
preload_trial,
write_headers,
pre_interaction_instructions,
interaction_trials,
final_screen
);
jsPsych.run(full_timeline);
}
Being able to specify your trial list ahead of time and save it as a CSV file can be useful in general and is something we will use again next week.
Exercises with the confederate priming experiment code
Attempt these problems. Once you have had a go, you can look at our notes which will be available after class.
- Run the basic
conferedate_priming.htmlexperiment and look at the CSV and audio data files it creates. Check you can access the audio, and that you can see how the audio and the trial list link up - how do you know which audio corresponds to which trial in the CSV? - Run it again and see where the data from the second run is stored - you may need to refresh your cyberduck window with the refresh button.
- The short trial list I built in
conferedate_priming.jsis for an overspecific confederate. How would you modify that trial list to simulate a minimally-specific confederate? - Now try running the
conferedate_priming_readfromcsv.htmlexperiment - you don’t have to work through the whole experiment, just a few trials! Again, check you can see your data on the server. - For this version of the experiment, how do you switch from an overspecific to minimally-specific confederate? (Hint: this involves changing the name of the file used by the
read_trials_and_prepare_timelinefunction in the very last line of the code). - [Harder] Building on the previous question: how would you randomly allocate a participant to one of these two conditions, overspecific or minimally specific? Once you have attempted this, you can look at my thoughts on how it could be done (which also covers the harder question later on).
- For either of these experiments, figure out how to disable image preloading for the button images and re-run the experiment. Can you see the difference? If it works smoothly, try running the experiment in Chrome in Incognito mode, which prevents your browser saving images etc for you. Can you see the difference now?
- [Harder, optional] Can you change the
random_waitfunction so it generates longer waits early in the experiment and shorter waits later on? Once you have attempted this, you can look at my thoughts on how it could be done.
References
Re-use
All aspects of this work are licensed under a Creative Commons Attribution 4.0 International License.